
Max Verhart
Het idee werd gelanceerd in het winternummer 2009 van Vuursteen: honderd haikudichters stellen elk één eigen gedicht beschikbaar – een gedicht waar hij/zij zelf heel tevreden over is. Aldus geschiedde. (zie pp. 93 t/m 96)
Er werden er zelfs teveel ingezonden, zodat de laatkomers teleurgesteld moesten worden. De honderd inzendingen werden geanonimiseerd aan alle deelnemers rondgezonden om de naar zijn of haar smaak tien beste te kiezen. Een stem op het eigen gedicht was daarbij uitgesloten. Waar het om te doen was, was nagaan hoe die voorkeuren verdeeld zouden zijn.
Afwegingen
Negenennegentig deelnemers gaven hun favoriete tien door. Enkelen deden dat snel, anderen namen de tijd. Dat is al meteen één aanwijzing voor hoe verschillend men tot keuzes komt. Naar afwegingen was niet gevraagd, maar sommigen lichtten hun keuze wel toe.
‘Soms is het moeilijk kiezen, dan moet je echt dubben en nadenken en nog eens herlezen en laten bezinken,’ schreef Johanna Kruit. ‘Bij mij geeft de doorslag dan altijd wel de 5-7-5 lettergrepen (…), boven een vers met meer of minder lettergrepen.’ Angeline Jansen constateerde echter dat vasthouden aan 5-7-5 nogal eens leidt tot gekunsteld taalgebruik (‘turkie-turkietaal’ noemt ze dat). Dus : twee verschillende dichters die op dat punt tegenstrijdig denken!
Zo vielen bij Angeline Jansen ook ‘veel verhaaltjes en sfeertekeningen’ af, omdat ze ‘weinig spanning en contrast’ hadden. Luk de Laat daarentegen ‘koos voornamelijk die werkjes er uit die een verhaal verbergen, of waarbij ik in mijn fantasie een leuk verhaal vermoed.’ Die tegenstelling is misschien minder concreet dan die tussen wel of geen voorkeur voor 5-7-5, maar je proeft er wel degelijk een verschillend beoordelingscriterium in.
Een ander contrast was dat sommigen moeilijk de tien beste gedichten konden kiezen omdat zij veel meer gedichten goed genoeg vonden, terwijl anderen in nog geen tien gedichten voldoende kwaliteit zagen. Het eerste standpunt vertolkten Gien de Smit (‘Ik had er eerst 20 en vind het best lastig om nog verder te moeten schiften – dan wordt het een beetje meedogenloos doen’) en Bep Grootendorst (‘Twintig haiku kiezen lukte vlot, maar van die twintig weer de tien beste was voor mij echt wikken en wegen’). Frans Kwaad verwoordde de tegengestelde ervaring: ‘Twee of drie verdienen een nominatie, meer niet. Er spreekt zo weinig vitaliteit en plezier, zo weinig kracht, energie en levenslust, zo weinig diepzinnigheid uit de inzendingen.’
Ida Gorter had een soortgelijke opvatting, maar trok er ook lering uit : ‘Eigenlijk had ik er maar vijf of zes die er voor mij metéén uitsprongen. (…) Ik vind het haast ontroerend om te weten dat dit haiku’s zijn die iedereen echt mooi en geslaagd vindt van zichzelf. Dat zo dus ook maar weinig mensen mijn haiku’s aan zullen spreken. Het is een lesje in nederigheid, ja, een levensles.’
Zulke toelichtingen laten zien dat voorkeuren en criteria van persoon tot persoon wisselen, soms slechts gradueel, maar ook wel substantieel. Maar ook de voorkeuren van één en dezelfde beoordelaar zijn niet altijd constant. Ze meldde Riet de Bakker : ‘Ik betrap me erop dat de “rangschikking” varieert van dag tot dag.’ Dat wil zeggen: de voorkeursvolgorde van haar favoriete tien wisselde van dag tot dag, al bleven het wel dezelfde tien favorieten.
Maar Adri van den Berg constateerde dat haar top tien zelfs van samenstelling kon veranderen: ‘Bij tweede lezing koos ik diverse anderen, en later kwam ik grotendeels terug op mijn eerste keuze. Ik merk dat, in het algemeen, mijn humeur – geduld – bekijken van mijn eigen criteria voor haiku – en zelfs het weer van de dag, waardering van een gedicht doen schommelen.’
Dat geeft allemaal enig inzicht in de motivaties van de verschillende keuzes en de manier waarop die tot stand komen. Enerzijds kunnen de voorkeuren van persoon tot persoon verschillen. Maar ook per persoon zelf kunnen de voorkeuren nog wisselen, afhankelijk van stemming, moment en ontvankelijkheid. Deze aspecten kan je de kwalitatieve kant van de zaak noemen. Maar waar mondde dat kwantitatief nou in uit ?
Puntenverdeling
Tabel 1 laat de scoreverdeling zien. De eerste kolom geeft het aantal punten weer dat aan een of meer gedichten werd toegekend. Kolom twee vermeldt het aantal gedichten dat die score haalde. Het totaal van deze kolom is uiteraard 100, namelijk het aantal deelnemende gedichten. De derde kolom is het product van die twee getallen: het totaal aantal punten per score. Voorbeeld: score 19 werd 4 keer gehaald, dus daar zijn 76 punten in betrokken. Het totaal van deze kolom
is uiteraard 990, namelijk de 99 x 10 punten die door de deelnemers werden toegekend (één deelnemer gaf immers geen keuze door). NB: scores die geen enkele keer voorkwamen (bijvoorbeeld 23, 25, 29) zijn weggelaten
Tabel 1: Voorkeursverdeling
score frequentie punten
0 6 0
1 7 7
2 8 16
3 8 24
4 6 24
5 4 20
6 2 12
7 4 28
8 6 48
9 7 63
10 2 20
11 3 33
12 6 72
13 3 39
14 3 42
15 4 60
16 2 32
17 1 17
18 2 36
19 4 76
20 1 20
21 1 21
22 2 44
24 2 48
26 1 26
27 1 27
28 1 28
30 1 30
36 1 36
41 1 41
100 990 Totaal
Wat was er te verwachten geweest ? Helaas is daarover vooraf geen hypothese geopperd. Maar het resultaat zou zich ongetwijfeld bevinden tussen twee uitersten: volmaakte overeenstemming tegenover totale verdeeldheid.
Volmaakte overeenstemming zou betekenen dat iedereen het eens was over de beste 10. Hadden alle honderd deelnemers hun scores ingeleverd, dan zouden tien gedichten elk 99 punten hebben gekregen. De auteurs van die tien mochten immers niet op hun eigen gedicht stemmen. Dus kozen zij een ander gedicht en bij volmaakte overeenstemming zou dat steeds hetzelfde gedicht zijn, zodat een elfde gedicht 10 punten had gekregen.
Bij totale verdeeldheid zouden alle stemmen gelijkmatig over alle gedichten verdeeld zijn. De 100 x 10 punten die er te verdelen waren zouden dus gelijkelijk over de honderd gedichten verdeeld zijn, zodat elk gedicht 10 punten zou hebben gekregen. Dat is gelijk aan het gemiddelde dat per gedicht beschikbaar was.
Normaalverdeling
Een hypothese had kunnen zijn dat de gemiddelde score het vaakst zou voorkomen en lagere en hogere scores minder vaak en verder dat hoe lager respectievelijk hoger de score uitviel, hoe minder vaak die zou voorkomen. Je zou dan de zg. normaalverdeling krijgen.
Zo’n normaalverdeling krijg je bijvoorbeeld als je de lengte van, ik noem maar wat, de bonen in een pondje sperziebonen meet. De meeste bonen zullen de gemiddelde lengte hebben of daar niet veel van afwijken. Maar hoe meer de lengte van het gemiddelde afwijkt, naar boven of naar beneden, hoe minder ervan zullen zijn.
hoe minder ervan zullen zijn.
Dat is wat je bij dergelijke metingen gewoonlijk vindt, vandaar de naam ‘normaal’-verdeling. Je kunt die in een grafiek weergeven: Figuur 1.
Op de liggende as staan de lengtematen van de bonen, bijvoorbeeld in millimeters, oplopend van kort tot lang, terwijl op de staande as per lengtemaat staat hoeveel er van die maat werden aangetroffen.
Volgens de hypothese dat de scores in ons onderzoek ook zo verdeeld zouden zijn, zou de score 10 het meest moeten voorkomen (de piek in Figuur 1), de scores 9 en 11 (links en rechts van de piek) wat minder, enzovoort. De laagste en de hoogste scores zouden volgens deze hypothese het minst moeten voorkomen (uiterst links en uiterst rechts in Figuur 1).
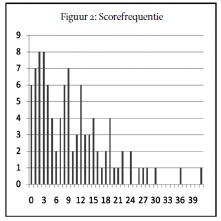 Maar dat beeld komt er bij de scorefrequentie (het aantal malen dat er op een gedicht gestemd is absoluut niet (Figuur 2) uit ! De score 10, die het hoogste zou moeten zijn, komt maar twee keer voor en de piek ligt bij de scores
Maar dat beeld komt er bij de scorefrequentie (het aantal malen dat er op een gedicht gestemd is absoluut niet (Figuur 2) uit ! De score 10, die het hoogste zou moeten zijn, komt maar twee keer voor en de piek ligt bij de scores
2 en 3, die juist laag zouden moeten zijn.
Dat lijkt niet op de normaalverdeling en de hypothese is dus onjuist. Het is eigenlijk niet mogelijk uit Tabel 1 en Figuur 2 heldere conclusies te trekken. Het
lijkt er nog het meest op dat er meer overeenstemming bestaat over wat men minder geslaagde haiku vindt dan over wat men goede haiku vindt. Maar er zitten rare pieken en dalen in het beeld. Kunnen we dat niet wat vereenvoudigen? Misschien dat het beeld dan wat helderder wordt.
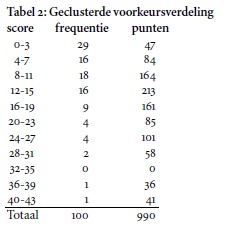 In Tabel 2 is Tabel 1 vereenvoudigd door steeds de totalen van vier opeenvolgende scores bij elkaar op te tellen (clusteren). Figuur 3 geeft de daaruit volgende scorefrequentieweer (tweede kolom van Tabel 2).
In Tabel 2 is Tabel 1 vereenvoudigd door steeds de totalen van vier opeenvolgende scores bij elkaar op te tellen (clusteren). Figuur 3 geeft de daaruit volgende scorefrequentieweer (tweede kolom van Tabel 2).
De grote onregelmatigheden zijn inderdaad verdwenen. Wat blijft is het opvallende gegeven dat de laagste scores (gedichten die 0 tot maximaal 3 punten kregen)
het meest voorkomen. Dat wijst inderdaad op een vrij grote mate van eensgezindheid waar het lage waardering betreft.
Maar vervolgens zien we ook dat de piek van de overige scores ligt bij de cluster 8-11, dus rond het gemiddelde, zoals volgens de inmiddels verworpen hypothese
verwacht had mogen worden. En afgezien van die opmerkelijk uitschieter links, ziet de figuur er overigens wel degelijk enigszins als een normaalverdeling uit.
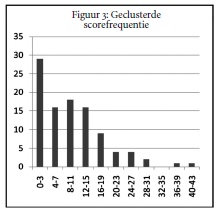 Maar nu moet niet uit het oog verloren worden dat puur rekenkundig lage scores veel meer kunnen voorkomen dan hoge. Het aantal gedichten dat 0 punten had kunnen krijgen is maximaal 89 (als 89 namelijk 10 gedichten elk 99 punten hadden gekregen en een elfde de overige 10), terwijl een score van bijvoorbeeld 50 punten maximaal maar 20 keer kan voorkomen, aangezien er maar 1000 punten te verdelen waren. Dus laten we eens kijken hoe de punten over de scores verdeeld waren (der kolom in Tabel 2, Figuur 4).
Maar nu moet niet uit het oog verloren worden dat puur rekenkundig lage scores veel meer kunnen voorkomen dan hoge. Het aantal gedichten dat 0 punten had kunnen krijgen is maximaal 89 (als 89 namelijk 10 gedichten elk 99 punten hadden gekregen en een elfde de overige 10), terwijl een score van bijvoorbeeld 50 punten maximaal maar 20 keer kan voorkomen, aangezien er maar 1000 punten te verdelen waren. Dus laten we eens kijken hoe de punten over de scores verdeeld waren (der kolom in Tabel 2, Figuur 4).
Nu ligt de piek bij de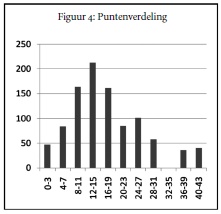 cluster van gedichten die 12 tot 15 punten kregen – iets boven het gemiddelde dus. De figuur heeft wel iets van de normaalverdeling, zij het met de piek wat verschoven naar een iets hogere waarde dan het gemiddelde. Kunnen
cluster van gedichten die 12 tot 15 punten kregen – iets boven het gemiddelde dus. De figuur heeft wel iets van de normaalverdeling, zij het met de piek wat verschoven naar een iets hogere waarde dan het gemiddelde. Kunnen
we daar iets uit opmaken?
Toevalskromme
Om daar wat over te zeggen eerst iets over een andere naam voor de normaalverdeling: toevalskromme. De normaalverdeling komt namelijk ook wel tevoorschijn als je het toeval zijn gang laat gaan. Een voorbeeld is de knikkerbak: een platte vierkante bak met een vooren achterwand waar precies een knikker tussen past. De voorwand is doorzichtig, de achterwand zit vol met regelmatig geplaatste spijkers. Bovenin zit een gat waardoor een knikker past. Die valt precies bovenop de eerste spijker en kan dan hetzij naar links, hetzij naar rechts vallen: dat bepaalt het toeval. Maar daarna valt hij op de volgende spijker en wederom bepaalt het toeval welke kant hij ‘kiest’. Pas na tientallen van die ‘keuzemomenten’ valt hij op de bodem.
Valt hij even vaak naar links als naar rechts, dan komt hij dus onderin het midden uit. Maar hoe vaker hij naar links valt, hoe linkser hij dus uiteindelijk de onderkant bereikt. Doe je dat nu met bijvoorbeeld duizend knikkers achter elkaar, dan vormen de knikkers, tátátátáá!, op de bodem gestapeld het patroon van de normaalverdeling! Vandaar de naam toevalskromme.
Terug naar onze puntenverdeling. Zou het toeval aan het werk geweest zijn, dan had de piek moeten liggen bij de gedichten die 10 punten hadden gekregen. Maar de piek blijkt tussen de 12 en 15 te liggen! En dat wijst er dus op dat er wel degelijk sprake is van een zekere overeenstemming in voorkeuren.
Conclusies
– Het resultaat van het onderzoek bevindt zich, zoals te verwachten was, tussen het ene uiterste van volmaakte overeenstemming en het andere van totale verdeeldheid.
– Het ziet er naar uit dat er een vrij grote mate van overeenstemming bestaat over wat als lage kwaliteit in een haiku beschouwd wordt.
– Tegelijk is er een lichte tendens waarneembaar die op een zekere mate van overeenstemming in positieve waardering wijst.
– Op een glijdende schaal tussen volmaakte overeenstemming en totale verdeeldheid ligt het resultaat iets dichter bij het eerstgenoemde dan bij het laatstgenoemde uiterste.
– Met andere woorden, de verdeeldheid in voorkeuren is erg groot, maar niet geheel toevallig.
– Hoe groot de verdeling is blijkt vooral uit het feit dat maar liefst 94 van de 100 gedichten één of meer punten kregen. Met andere woorden: 94 van de 100 gedichten behoorden tot de top tien van tenminste één andere deelnemer!
Wedstrijdelement
Het bovenstaande is een puur technische analyse van de cijfermatige gegevens, waar de gedichten zelf geen rol in spelen. Daar ging het ook om. Maar sommige deelnemers noemden dit onderzoekje niettemin een ‘wedstrijd’. En ja, al was dat niet bedoeld, er zat inderdaad iets in dat kan worden opgevat als wedstrijdelement. De methodiek is immers die van een kukai: een haikuwedstrijd, waarin de deelnemers tevens de jury zijn.
Met een overzicht van alle gedichten die tenminste één stem behaalden besluit daarom deze beschouwing. U treft daarbij van laag naar hoog de scores aan, gevolgd door de nummers van de gedichten met die score. De genummerde gedichten met auteursnamen heeft u vast al in (of bij) dit nummer van Vuursteen aangetroffen. U kunt dus zelf makkelijk terugvinden welk gedicht hoeveel punten behaalde. Alleen het identificeren van de 0-scores is iets lastiger…
Maar laten we het wedstrijdelement nog wat meer recht doen, door hier allereerst de drie gedichten met de hoogste scores te vermelden.
De nummers drie, twee en één:
in het grasveld
is een paadje gegroeid
van voetstappen Riet De Bakker (30 punten)
IJs van een nacht –
het kan niet meer dragen
dan mijn schaduw. Adri van den Berg (36 punten)
achter mijn rug
hobbelt haar stemmetje mee
over de keien Marlène Buitelaar (41 punten)