
Hans Reddingius
Dit stukje gaat over getallen. Dat lijkt nogal saai. Maar getallen kunnen soms iets nauwkeuriger vertellen dan in woorden mogelijk is, en dan wordt het toch nog wel eens interessant. Ik wil het hebben over het onderzoek van Max Verhart aangaande voorkeuren van haikuliefhebbers.
Max vroeg 100 dichters om ieder een haiku in te sturen; vervolgens kregen deze dichters alle aldus ingezamelde haiku’s toegestuurd zonder vermelding van de auteursnaam, met het verzoek te melden wat volgens hen de beste tien haiku’s waren. De resultaten heeft Max besproken in het artikel ‘Haiku’s kiezen: zoveel kiezers, zoveel voorkeuren?’ Dit stukje bevat wat commentaar op het onderzoek en een paar aanvullingen.
Het onderzoek is interessant, maar aan de opzet kleven een paar bezwaren.
In de eerste plaats : de anonimiteit was maar betrekkelijk. Als deelnemer herkende ik nogal wat haiku’s omdat ze al lang tot mijn favorieten behoorden. Het is dan vrij moeilijk om toch op alle verzen even onbevangen te reageren; bovendien wist ik wie de auteurs waren.
In de tweede plaats : de deelnemers mochten niet hun eigen haiku beoordelen. Dat maakt de berekeningen een beetje lastig.
In de derde plaats : de deelnemers mochten ieder tien en slechts tien haiku’s als de beste uitkiezen. Dat introduceert een afhankelijkheid in de gegevens. Als een haiku namelijk toevallig wat meer punten krijgt dan gemiddeld, dan krijgt of krijgen andere haiku’s automatisch wat minder, en vice versa. Vergelijk dit met het door een paar deelnemers gemelde probleem: de twintig beste uitkiezen was goed te doen, maar daaruit weer de tien beste was een beetje arbitrair.
Tot zover het commentaar. Nu de aanvulling. Ik heb een manier bedacht om de mate van overeenstemming tussen de beoordelingen in een getal uit te drukken. Om duidelijk te maken hoe ik daaraan kom ga ik er even gemakshalve van uit dat alle deelnemers een beoordeling hadden ingezonden (in plaats van slechts 99 van de 100). Stel die 100 beoordelaars waren het perfect eens geweest, en dat de verzen zo gerangschikt waren dat vers nummer 1 volgens iedereen het beste was, vers nummer 2 het op één na beste enzovoorts, tot vers 100 het slechtste. Elk van de verzen 1 tot en met 10 hadden dan van elk van de beoordelaars nummers 1 tot en met 10 ieder een punt gekregen, op één na, want de beoordelaars mochten hun eigen vers geen punt toekennen.
Het tiende punt dat zo’n beoordelaar nog weg te geven had, gaf zij/hij dan in vredesnaam maar aan vers nummer 11. De verzen 1 tot en met 10 kregen dus ieder tot dusver 9 punten, en vers 11 kreeg 10 punten.
De overige 90 beoordelaars gaven ieder een punt aan elk van de verzen 1 tot en met 10. Daardoor kregen de verzen 1 tot en met 10 ieder in totaal 9 + 90 = 99 punten, en vers 11 hield er 10. In totaal dus 10 x 99 + 10 = 1000 punten, oftewel 100 keer 10. Deze cijfers zijn als volgt overzichtelijk samen te vatten:
Tabel A
score frequentie afwijking gemiddelde absolute afwijking gem.
0 89 -10 10
10 1 0 0
99 10 +89 89
In deze tabel zie je ook de afwijkingen van het gemiddelde. Er waren 100 x 10 = 1000 punten te verdelen over 100 verzen, dat is gemiddeld 10 punten per vers. Een vers dat 0 punten kreeg heeft dan 10 punten minder dan het gemiddelde (-10); een vers dat 99 punten kreeg had er 89 meer dan het gemiddelde (+89). De afwijking –10 kwam 89 keer voor, de afwijking 0 kwam één keer voor en de afwijking +89 kwam tien keer voor. De som van al die afwijkingen is dus –10 x 89 + 0 x 1 + 89 x 10 = 0.
De gemiddelde afwijking van het gemiddelde is 0. Nogal wiedes, daar is het gemiddelde het gemiddelde voor. Als je er echter alleen naar kijkt hoe groot de afwijking is en niet of die negatief of positief is, krijg je de absolute afwijking van het gemiddelde. Dat zie je in de laatste kolom van tabel A. De gemiddelde absolute afwijking van het gemiddelde is een aardige maat voor hoezeer de scores onderling verschillen. In het geval dat we nu bespreken moet die zo groot zijn als maar kan: een beperkt aantal verzen krijgt het maximaal aantal punten dat een vers kan krijgen, een vers krijgt het gemiddelde, en de rest niets. De som van de absolute afwijkingen is 89 x 10 + 1 x 0 + 10 x 89 = 1780, en de gemiddelde absolute afwijking is dus 1780/100 = 17,80.
Bekijk nu het andere uiterste: er heerst absoluut geen overeen stemming tussen beoordelaars, en de punten worden gelijkmatig over alle verzen verdeeld: ieder vers krijgt gewoon 10 punten. We hebben geen tabel nodig om in te zien dat de gemiddelde absolute afwijking van het gemiddelde 0 is, immers geen enkele score verschilt van het gemiddelde, 10.
Bij een experiment zoals Max Verhart deed zal het resultaat ergens tussen die twee uitersten in liggen: er zal geen volstrekte consensus heersen, maar de verzen zullen toch niet allemaal precies 10 punten krijgen. Wanneer men dan een gemiddelde absolute afwijking van het gemiddelde berekent zal men een getal vinden dat tussen 0 en 17,80 in ligt. Als we dat getal delen door 17,80 krijgen we een getal dat tussen 0 en 1 ligt. Dat getal noem ik dan de concordantiecoëfficiënt c. Hoe dichter c bij 1 ligt, hoe groter de consensus ; hoe dichter bij 0, hoe groter gebrek aan consensus.
Doordat er in het geval van Max’onderzoek niet 100, maar slechts 99 beoordelaars waren, maar wel 100 verzen, wordt de berekening ietsje ingewikkelder. Bijvoorbeeld is het gemiddeld aantal punten per vers nu 9,9 in plaats van 10, maar een vers kan nooit 9,9 punten krijgen, de score zal altijd minstens 0,1 van het gemiddelde verschillen. De kleinst mogelijke waarde van de gemiddelde absolute afwijking van het gemiddelde blijkt nu 0,18 te bedragen, en de grootst
mogelijke waarde 17,622. Het verschil tussen die twee waarden is 17,442. Om c te berekenen gaan we nu eerst 0,18 van de gemiddelde absolute afwijking aftrekken, en het getal dat we dan hebben gekregen delen we door 17,442.
Voor de gegevens die Max Verhart verzamelde blijkt dat c = 0,371. Dat is flink wat groter dan 0, maar nog lang geen 1. Dat betekent dus: er was wel enige overeenstemming, maar die was verre van volledig. Dat wisten we natuurlijk al, maar ik vind het wel leuk om zoiets in een getal uitgedrukt te zien. Je vraagt je hierbij wel af in hoeverre je zo’n getal als 0,371 ook krijgt als de punten geheel volgens toeval over de verzen waren verdeeld. Doorgaans zal c dan niet precies 0 zijn maar wat groter. Hoeveel groter? Om daar een indruk van te krijgen heb ik een experiment gedaan. Stel dat iedere beoordelaar zijn punten gewoon zou verloten over de 99 verzen waaruit hij mag kiezen. Hij neemt een hoed met lootjes, genummerd 1 tot en met 100, en trekt er 10 lootjes uit. Zit zijn eigen nummer erbij, dan legt hij dat lootje even opzij en trekt nog een lootje. De nummers op de lootjes worden de nummers van de verzen die een punt krijgen. De
lootjes worden terug gedaan in de hoed, en goed geschud, en de tweede deelnemer doet hetzelfde als de eerste, en zo gaan we door tot we ze alle 99 hebben gehad. Als resultaat zijn de punten nu volgens loting, dus volgens toeval, verdeeld. Zo’n experiment heb ik gedaan, alleen heb ik in plaats van een hoed met lootjes een tabel met ‘toevalsgetallen’ gebruikt. Hieronder het resultaat.
Tabel B. Een geval van toevallige puntenverdeling
score frequentie absolute afwijking
4 2 5,9
5 3 4,9
6 7 3,9
7 11 2,9
8 15 1,9
9 12 0,9
10 8 0,1
11 14 1,1
12 10 2,1
13 5 3,1
14 4 4,1
15 5 5,1
16 2 6,1
19 2 9,1
Hieruit vinden we c = 0,133. Dat is nogal wat kleiner dan voor de gegevens van Max, en het lijkt er dus op dat de consensus bij de beoordeling van haiku’s wel wat groter is dan je volgens puur toeval zou verwachten.
Het is misschien aardig om ook in dit geval nog even te kijken naar een grafiek van de verdeling van de scores. Zie Figuur 1.
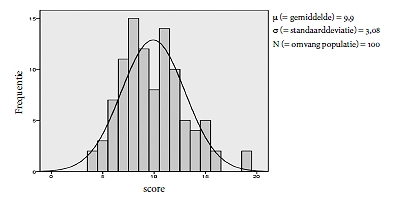
Afgezien van toevallige ups en downs lijkt dit meer op een symmetrische verdeling rond een gemiddelde dan de verdeling van de beoordelingen van de 100 haiku’s. Zoals ik in mijn commentaar al zei : ik vermoed dat de toevallige ups en downs elkaar versterkt hebben en dat deze figuur wel een aardig beeld geeft van wat je bij een toevallige verloting van punten over 100 plekjes kunt verwachten.
Vergelijking met de gegevens van Max laat nog iets meer zien. Scores lager dan 4 komen in mijn toevalssimulatie niet voor en bij Max wel. Scores hoger dan 19 komen in het toevalsgeval ook niet voor en bij Max wel; daar komt zelfs scores van 36 en 41 voor, wat in een toevallige verdeling nu wel erg onwaarschijnlijk lijkt. Blijkbaar was er overeenstemming over wat niet zo erg goede haiku’s waren, maar ook over wat de beste waren.
Waarom laten haikudichters zich in met deze flauwekul? Deze jongen steekt zijn tijd liever in goede en klassieke haiku’s (en geen ‘haiku’ want dat is Engels) schrijven. Ik zie geen enkele waarde in dit artikel, temeer als je bedenkt hoe betrekkelijk het is wat een goede haiku is. Want dat is subjectief, gebaseerd op meningen, stemmingen, gevoelens, die wisselen. Wat men vandaag een goede haiku vindt, vindt men morgen weer niet.